データベースとは
「データベース」とは、ある特定の条件に当てはまる「データ」を複数集めて、後で使いやすい形に整理した情報のかたまりのことを表します。
特にコンピュータ上で管理するデータをデータベースと呼ぶことが多いですが、紙の上で管理する「電話帳」や「住所録」なども、立派なデータベースです。
また、コンピュータ上でデータベースを管理するシステム(DBMS:Database Management System)のことや、
そのシステム上で扱うデータ群のことを、単に「データベース」と呼ぶ場合もあります。
データベース管理システム(DBMS)の役割
紙の住所録ではなくコンピュータ上のデータベースとしてDBMSを使用する最大のメリットは、やはり「大量のデータを自動的に整理してくれる」という点です。
多くても数百件程度の個人の住所録ならば手動で管理することも可能ですが、法人で扱う数万件のデータをいちいち手で整理するには膨大な人手や時間が必要になります。
アナログデータをコンピュータに入力するところはまだ人力がメインな現状ですが、数万件のデータを一瞬にしてあいうえお順などにソートするなどのアシストをDBMSは担っています。
データベースの種類
データベースは3種類に分けられます。それぞれの特長を紹介します。
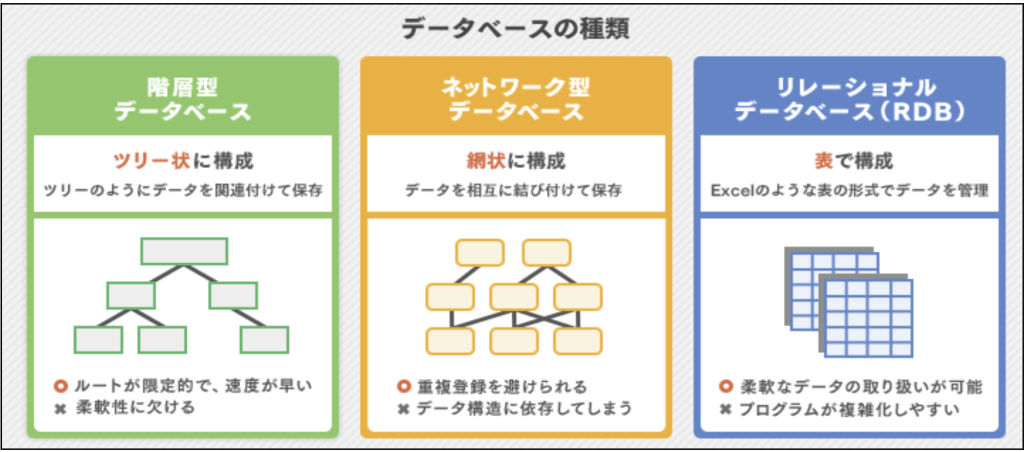
ツリー状に構成する「階層型データベース」
階層型データベースとは、ツリーのようにデータを関連付けて保存するタイプです。
会社の組織図のように、上層から下層に分岐する1対多の形でデータが整理されています。
上層から特定のデータに至るまでのルートは一つのみのため、データの検索が早いという特長があります。
しかし、データが重複する場合は注意が必要です。
網目状に構成する「ネットワーク型データベース」
ネットワーク型データベースとは、関連性のあるデータを相互に結び付けて保存するタイプです。
階層型データベースを、下層から上層に向けても分岐させた形式のデータベースといえるでしょう。
これにより、多対多の関係性が成り立つと同時に、情報の重複登録が避けられます。
表で構成する「リレーショナルデータベース(RDB)」
リレーショナルデータベースは、Excelのような表の形式でデータを管理するタイプです。
関係データベースともいいます。エクセルでいうシートを「テーブル」といい、列を「フォールド」、行を「レコード」と呼びます。
フィールドには項目が入り、レコードには項目ごとに該当するデータが入ります。
テーブル同士を組み合わせて見ることもできるので、複雑に関連している情報でも整理がしやすくなります。
また、表形式であるため、人が視覚的に理解しやすいのも長所といえるでしょう。現在はこのリレーショナルデータベースが主流となっています。
ただし、データを管理するプログラム自体が複雑になるというデメリットもあります。
データベース管理システム(DBMS)の主な製品
主要なRDBMS
Oracle Database
単に「Oracle」とも表記される、Oracle社製のRDBMSです。
高可用性、スケーラビリティ、セキュリティに優れており、大規模な基幹システムやミッションクリティカルなシステムで世界的に高いシェアを誇っています。特に日本国内では、長らくエンタープライズ分野のデファクトスタンダードとして君臨しています。
MySQL
MySQLはオープンソース(OSS)のRDBMSであり、Webアプリケーション開発において非常に高いシェアを誇ります。
小規模な個人プロジェクトから、FacebookやGoogleといった大規模サービスまで幅広く利用されています。商用利用の場合はライセンスの購入が必要となりますが、有償ソフトウェアとほぼ遜色ない機能を持っており、近年では法人向けにも多く利用されています。
SQLServer
Microsoft社製の商用RDBMSです。Windows環境との親和性が非常に高く、特に中小企業や.NET Frameworkを利用したシステムで広く採用されています。GUIベースの管理ツールが充実しており、データベース管理が比較的容易な点も特徴です。クラウドサービス「Azure」との連携も強力です。
PostgreSQL
オブジェクトリレーショナルデータベースとしても知られる、オープンソースのRDBMSです。MySQLと並び、OSSの代表格として非常に高い人気を誇ります。標準SQLへの準拠度が高く、高度なデータ型や複雑なクエリにも対応しているため、堅牢性や機能の豊富さが求められるシステムでよく選ばれます。学術研究や大規模なデータ分析などにも利用されることがあります。
DB2
IBM社製の商用RDBMSです。IBM社製の商用RDBMSです。主に同社のメインフレームやUNIXシステムと連携して採用されることが多く、金融機関や官公庁、大企業の基幹システムといった高信頼性が要求される大規模システムで利用されています。高度なデータ管理機能や高いパフォーマンスが特徴です。
その他
「SQLite」、「Microsoft Access」、「Microsoft Azure SQL Database」など
データベースの周辺知識
SQLとは
SQLとはデータベースを操作するための言語のことであり、DBMS上でデータの追加や削除、並べ替えなどを行うようコンピュータに命令するための手段です。
基本的に1行ずつ入力して確定し、直ちに実行されます。複数のSQLを組み合わせて大きな一つの塊のSQLとして実行することもできますが、通常のプログラミング言語のように一連の操作をまとめてセットすることのできる「ストアドプロシージャ」という機能のあるDBMSもあります。
なお、SQLはどのデータベースであっても基本的には共通の命令を使用していますが、DBMSの製品によりその製品専用のSQLなども存在しています。移植の際には注意が必要です。
ストアドプロシージャとは
ストアドプロシージャとは、if文の条件分岐やfor文のループをSQLと組み合わせて、通常のプログラミング言語のような感覚でデータベースを操作することのできるDBMSの機能です。
アプリケーションからデータベースを呼び出してデータを使用する場合、アプリケーション本体のプログラムからSQLを1行ずつ発行してデータを操作するケースと、ストアドプロシージャを呼んでまとめて結果だけを受け取るというケースがあり、用途によって使い分けられています。
データベースに関する用語
スキーマ
スキーマとは、データベースの構造を定義したものです。
データベースのデータをどう管理するかの、一連の約束を意味します。
データベースをExcelとして例えた場合、エクセルファイルそのものです。
テーブル
テーブルとはデータを配置するシートに相当する用語です。
リレーショナルデータベースではプログラムの利便性やデータの種類などを考慮し、複数のテーブルを用意して、必要に応じて組み合わせて条件に合うデータを抽出します。
フィールド
フィールドとはレコードを構成する最小の構成要素を意味する用語です。
データベースをExcelとして例えた場合、フィールドは「セル」に該当します。
テーブルの中にあるもっとも小さい構成要素がフィールドです。
このフィールドの集合体の縦列を「カラム」と呼び、行を「レコード」と呼びます。
レコード
レコードとはデータそのものを意味する用語です。
テーブルで見た場合、レコードは水平方向にあるセルが集まったもので、Excelで例えると「行」のことになります。
この横に伸びるレコード1本1本がデータとなります。
また、行のことをロウ(Row)と呼ぶ場合もあるため、覚えておくとよいでしょう。
カラム
カラムとは属性に相当する用語です。
カラムは属性を意味するもので、Excelで例えると垂直方向に伸びる「列」に該当します。
データベースではカラムごとに「文字列」や「数値」といった属性が決まっているため、属性のことをカラムと呼ぶケースもあります。
SQL
SQLとはデータベースを扱うためのプログラミング言語です。
リレーショナルデータベースを操作するための言語で、「Structured Query Language」を略した名称です。
SQLはデータベース言語としてISOで規格化されています。
クエリ
クエリとはデータベースへの処理要求を文字として表したものです。
ユーザーがSQLを使ってデータベースを操作する場合、実際に処理を走らせるために使用する文字列がクエリです。
データの検索や抽出、テーブルへのデータの追加や更新、削除などの要求を行う場合に使用されます。
また、クエリを記述するための標準的な言語がSQLとなっており、クエリは一度作成すれば繰り返し再利用できるようになっています。
論理名と物理名
論理名とは「人間に分かりやすい名前、呼び方」のことで、物理名は「実際のプログラム上で使用される名前」です。
例えば、論理名が「ユーザーテーブル」で、物理名が「users」といった形です。
一般に、テーブル名やカラム名には英字と記号を使用した名前(物理名)を付けます。
基本的なデータ型
SQLで利用可能なデータ型は、かなりの数が存在します。
しかし、頻繁に利用するデータ型というのはある程度決まっており、ここでは3つのカテゴリを説明していきます。
文字列型
カラムを作成する際にサイズ指定を行う必要があり、指定サイズ以上の文字列は格納することが出来ない。
| CHAR型 | 決められたサイズのデータ領域を確保する型。指定したサイズに足りない場合は、末尾が空白で埋められる(固定長) |
|---|---|
| VARCHAR型 | 格納する文字列によって確保するデータ領域が適宜変更される型。指定したサイズ以内の文字列が保存できる(可変長) OracleではデフォルトはByte単位で、文字数単位で指定する場合は明記する必要あり |
数値型
各データ型により扱える数値の範囲が異なります。
| 整数型 | 符号付き | 符号なし |
|---|---|---|
| TINYINT | -128~127 | 0~255 |
| SMALLINT | -32768~32767 | 0~65535 |
| MIDIUMINT | -8388608~8388607 | 0~16777215 |
| INT INTEGER | -2147483648~2147483647 | 0~4294967295 |
| BIGINT | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
| 浮動小数点型 | ||
|---|---|---|
| FLOAT型 | 小数第7位までが正確な値 | |
| DOUBLE型 | 小数第15位までが正確な値 | |
日付型
| DATE型 | 日付(年月日)を格納する 基本フォーマットは「YYYY-MM-DD」 |
|---|---|
| TIMESTAMP型 | 日時(年月日時分秒)を格納する 基本フォーマットは「YYYY-MM-DD HH:MM:SS」 |
制約とは
制約とはデータベースに格納されるデータに制約条件を付けるものです。
例えば、NOT NULL制約が設定されている項目はNULLを許容しませんので、必ず値がセットされなければなりません。
制約を設定した列に、値を指定せずにデータを格納しようとしても、RDBMSが制約違反ということでエラーを返します。
OracleやSQL Serverなどの通常のRDBMSにも実装されています。
RDBMSで実装している制約には、下表のようなものがあります。
| 制約 | 内容 |
|---|---|
| 一意制約 | 一意を保証して、インデックス情報を持つので検索が高速化される。(NULL以外の重複する値が存在しない) 主キー制約との違いは、テーブルに1つとは限らず複数設定できることと、NULLを許可すること。 |
| 主キー制約 | テーブルに1つ設定するもので、そのキーを指定すればデータ(行)が特定できるもの。 一意制約とNOT NULL制約の両方を満たす状態。 多くの場合、自動インクリメントされる数値(1,2,3,,,)を使用する。 |
| NOT NULL制約 | NULL(値が入っていない状態)でないことを保証する制約。 |
| チェック制約 | 任意の制約条件に違反した値が入らないことを保証する制約。 例えば、in(1,2)という制約条件を設定すると、その列には1か2しか格納できなくなる。 |
| 外部キー制約 (参照整合性制約) | 他のテーブルとの整合性を確保するために制約。 例えば、受注テーブルの顧客番号(外部キー)と顧客テーブルの顧客番号(主キー)に設定すると、顧客テーブルに存在しない顧客番号を受注テーブルにセットできなくなる。 |
| デフォルト制約 | 項目の初期値をセットする機能で、厳密には制約的な機能ではないが便宜上制約として扱っている。 例えば、数量という列に1というデフォルトを設定しておくと、値を指定しない場合に1がセットされる。 |
これらの制約は、あるからといって必ず使うとは限りません。
主キー制約とNOT NULL制約くらいしか使っていないというシステムも非常に多くあります。
Oracle Databaseのインデックス
インデックスとはテーブルに格納されたデータの一部を取り出し検索用に最適化したもので、
膨大なデータが格納されているテーブルなどでインデックスを作成するとデータの検索を高速に行うことができる場合があります。
作成された索引はデータベースによって自動的にメンテナンスされ使用されます。
ただし無闇にインデックスを増やすと、かえってパフォーマンスが低下する恐れもありますので注意が必要です。
一意索引
索引には、一意索引と非一意索引の2種類があります。一意索引を使用すると、重複した値が入らないことが保証されます。
主キー制約または一意制約を付与すると、自動的にインデックスが作成されます。
Oracle Databaseでは、上記のほか索引タイプ(Bツリー索引、ビットマップ索引など)を選択してインデックスを付与することが出来ます。
マニュアルでは詳細には扱いませんが、インデックスの役割については知識として押さえておきましょう。
参考サイト
インデックスとは?仕組みをわかりやすく解説